Главная Обратная связь
Дисциплины:
Архитектура (936)
Биология (6393)
География (744)
История (25)
Компьютеры (1497)
Кулинария (2184)
Культура (3938)
Литература (5778)
Математика (5918)
Медицина (9278)
Механика (2776)
Образование (13883)
Политика (26404)
Правоведение (321)
Психология (56518)
Религия (1833)
Социология (23400)
Спорт (2350)
Строительство (17942)
Технология (5741)
Транспорт (14634)
Физика (1043)
Философия (440)
Финансы (17336)
Химия (4931)
Экология (6055)
Экономика (9200)
Электроника (7621)

Классификация алгоритмов маршрутизации
|
|
Классификация алгоритмов маршрутизации (рис. 58) производится в зависимости от направления передачи пакетов и способов представления данных, топологии и нагрузки сети.
Простая маршрутизация — способ маршрутизации, не изменяющийся при изменении топологии и состояния СПД. Обеспечивается разными алгоритмами, типичными из которых являются алгоритмы случайной и лавинной маршрутизации.

Рис. 58 — Классификация алгоритмов маршрутизации
Случайная маршрутизация — передача пакета из узла в любом, случайным образом выбранном направлении, кроме направления, по которому пакет поступил в узел. Пакет, совершая блуждания по сети, с конечной вероятностью когда-либо достигает адресата. Случайная маршрутизация неэффективна ни по времени доставки пакета, ни по использованию пропускной способности сети.
Лавинная маршрутизация — передача пакета из узла во всех направлениях, кроме того, по которому поступил пакет. При этом, если узел связан с n другими узлами СПД, пакет передается в nнаправлениях, то есть размножается. Очевидно, что хотя бы одно направление обеспечит доставку пакета за минимальное время, то есть лавинная маршрутизация гарантирует малое время доставки, однако при этом резко ухудшается использование пропускной способности СПД из-за загрузки ее большим числом пакетов.
Маршрутизация по предыдущему опыту — передача пакета в направлении, выбираемом на основе потока, проходящего через узел. При этом пакеты, поступая в сеть, снабжаются адресами получателя и источника и счетчиком числа пройденных узлов (числа ретрансляционных участков). Пакет, пришедший в узел со значением счетчика 1, определяет соседний узел; пакет со значением счетчика 2 определяет узел, находящийся на расстоянии двух шагов, и т.д. Эти данные позволяют установить топологию сети и на ее основе построить таблицу для выбора маршрута. Постоянно анализируя число пройденных узлов, можно изменять таблицу маршрутов, если появился пакет с числом пройденных узлов, меньшим ранее зарегистрированного. Этот способ маршрутизации позволяет узлам приспосабливаться к изменению топологии сети, однако процесс адаптации протекает медленно и неэффективно. Метод изучения пути передачи пакетов используется для построения ряда модификаций алгоритмов простой маршрутизации.
Простая маршрутизация, не обеспечивая направленной передачи пакетов от источников к адресатам, имеет низкую эффективность! Основное ее достоинство — обеспечение устойчивой работы СПД при выходе из строя различных частей сети.
Фиксированная маршрутизация — способ выбора направления передачи по таблице маршрутизации, устанавливающей направление передачи для каждого узла назначения. Таблицы маршрутизации определяют кратчайшие пути от узлов к адресатам и вводятся в узлы связи от управляющего центра сети. Для слабо загруженных сетей этот способ маршрутизации дает хорошие результаты, но его эффективность падает по мере увеличения нагрузки на сеть. При отказе линий связи необходимо менять таблицу маршрутизации. При возникновении отказа по узлам сети рассылается управляющий пакет, содержащий сведения об отказе, реагируя на который, узлы меняют таблицы маршрутизации. Очевидно, что разработать способ фиксированной маршрутизации, обеспечивающей работоспособность сети при отказе многих линий, является чрезвычайно трудной задачей. К тому же фиксированная маршрутизация не позволяет адаптироваться к изменениям нагрузки, что приводит к значительным задержкам пакетов в СПД. Фиксированная маршрутизация может строиться на основе единого пути передачи пакетов между двумя абонентами. Такой способ называется однонаправленной маршрутизацией. Его недостаток — неустойчивость к отказам и перегрузкам. Для повышения устойчивости в таблицах маршрутизации указывается несколько возможных путей передачи пакета и вводится правило выбора целесообразного пути. Такой способ называется много направленной маршрутизацией.
Адаптивная маршрутизация — способ выбора направления передачи, учитывающий изменение состояния СПД. При адаптивной маршрутизации узлы СПД принимают решение о выборе маршрутов, реагируя на разного рода данные об изменении топологии и нагрузки. В идеальном случае каждый узел сети должен располагать полной информацией о текущем состоянии всех остальных узлов, топологии сети и длине очередей к каждому направлению в каждом узле. Однако, даже в этом идеальном случае задержки в СПД лишь немногим меньше, чем при фиксированной маршрутизации, таблицы которой определяют кратчайшие пути в сети и не изменяются при колебаниях нагрузки. Дело в том, что оптимальные маршруты, формируемые на основе самой «свежей» информации о распределении нагрузки в сети, становятся неоптимальными в последующие моменты времени, когда пакеты еще не достигли адресатов. Когда, например, сильно загруженные узлы получают информацию о том, что некоторая часть сети загружена слабо, они одновременно направляют пакеты в эту часть сети, создавая в сети, быть может, худшую ситуацию, чем предшествующая. Таким образом, алгоритмы адаптивной маршрутизации не обеспечивают оптимальности маршрутов. Однако выбор даже не оптимального, а близкого к нему маршрута приводит к значительному уменьшению времени доставки, особенно при пиковых нагрузках, а также к некоторому увеличению пропускной способности сети. Поэтому адаптивная маршрутизация получила широкое применение в вычислительных сетях, и в первую очередь в сетях с большим числом узлов связи (10 и более).
Алгоритмы адаптивной маршрутизации классифицируются по информации, используемой ими для принятия решений при назначении маршрутов. Локальная адаптивная маршрутизация основана на использовании информации, имеющейся в отдельном узле СПД. Эта информация включает в себя:
· таблицу маршрутизации;
· данные о текущем состоянии каналов (работают или нет);
· длину очередей пакетов, ожидающих передачи.
Информация о состоянии других узлов сети не используется. Таблицы маршрутизации указывают кратчайшие маршруты, проходящие через минимальное количество узлов и обеспечивающие передачу пакета в узел назначения за минимальное время.
Распределенная адаптивная маршрутизация основана на использовании информации, получаемой от соседних узлов сети. Этот способ маршрутизации может реализоваться, например, следующим образом. Каждый узел сети формирует таблицы маршрутов ко всем узлам назначения, минимизирующие задержки в сети, причем для каждого маршрута указывается фактическое время передачи пакета в узел назначения. До начала работы сети это время оценивается исходя из топологии сети. В процессе работы сети узлы регулярно обмениваются с соседними узлами таблицами задержки. После обмена каждый узел пересчитывает задержки с учетом поступивших данных и длины очередей в самом узле. Пакет ставится в очередь к маршруту, который характеризуется минимальным временем доставки. Обмен таблицами задержки производится периодически или в том случае, если обнаруживаются существенные изменения задержки из-за изменения очередей на передачу или состояния линий связи вследствие отказа. Периодический обмен таблицами задержки значительно увеличивает загрузку сети, а асинхронный снижает. Однако в каждом случае загрузка остается весьма существенной, и к тому же сведения об изменении состояния узлов медленно распространяются по сети. Так, при обмене с интервалом 2/3 секунды время передачи данных составляет несколько секунд, и в этот период узлы направляют пакеты по старым путям, что может создать перегрузку в районе вышедших из строя компонентов сети.
Централизованная адаптивная маршрутизация основана на использовании информации, получаемой от центра маршрутизации. При этом каждый узел сети формирует сообщения о своем состоянии, длине очередей, работоспособности линий связи, и эти сообщения передаются в центр маршрутизации. Последний на основе полученных данных формирует таблицы маршрутизации, рассылаемые всем узлам сети. Неизбежные временные задержки при передаче данных в центр маршрутизации, формировании и рассылке таблиц приводят к потере эффективности централизованной маршрутизации, особенно в ситуациях, когда нагрузка сильно пульсирует. Поэтому централизованная маршрутизация по эффективности не превосходит локальную адаптивную, а кроме того, отличается специфическим недостатком — потерей управления сетью при отказе центра маршрутизации.
Гибридная адаптивная маршрутизация основана на использовании таблиц, периодически рассылаемых центром маршрутизации, в сочетании с анализом длины очередей в узлах. Если таблица маршрутизации, сформированная для узла связи центром, определяет единственное направление передачи пакета, то пакет передается именно в этом направлении. Если же таблица определяет несколько направлений, то узел выбирает направление в зависимости от текущих значений длин очередей по алгоритму локальной адаптивной маршрутизации. Гибридная маршрутизация компенсирует недостатки централизованной и локальной: маршруты, формируемые центром, являются устаревшими, но соответствуют глобальному состоянию сети; локальные алгоритмы являются «близорукими», но обеспечивают своевременность решений.
Протоколы маршрутизации
RIP
Этот протокол маршрутизации предназначен для сравнительно небольших и относительно однородных сетей (алгоритм Беллмана–Форда). Протокол разработан в университете Калифорнии (Беркли). Маршрут здесь характеризуется вектором расстояния до места назначения. Предполагается, что каждый маршрутизатор является отправной точкой нескольких маршрутов до сетей, с которыми он связан. Описания этих маршрутов хранятся в специальной таблице, называемой маршрутной. Таблица маршрутизации RIP содержит по записи на каждую обслуживаемую машину (на каждый маршрут). Запись должна включать в себя:
· IP-адрес места назначения.
· Метрику маршрута (от 1 до 15; число шагов до места назначения).
· IP-адрес ближайшего маршрутизатора (gateway) по пути к месту назначения.
· Таймеры маршрута.
Первым двум полям записи мы обязаны появлению термина вектор расстояния (место назначения — направление; метрика — модуль вектора). Периодически (раз в 30 сек) каждый маршрутизатор посылает широковещательно копию своей маршрутной таблицы всем соседям — маршрутизаторам, с которыми связан непосредственно. Маршрутизатор — получатель просматривает таблицу. Если в таблице присутствуют новый путь или сообщение о более коротком маршруте, либо произошли изменения длин пути, эти изменения фиксируются получателем в своей маршрутной таблице.
В протоколе RIP сообщения инкапсулируются в udp-дейтограммы, при этом передача осуществляется через порт 520. В качестве метрики RIP использует число шагов до цели. Если между отправителем и приемником расположено три маршрутизатора (gateway), считается, что между ними 4 шага. Такой вид метрики не учитывает различий в пропускной способности или загруженности отдельных сегментов сети. Применение вектора расстояния не может гарантировать оптимальность выбора маршрута, ведь, например, два шага по сегментам сети Ethernet обеспечат большую пропускную способность, чем один шаг через последовательный канал на основе интерфейса RS-232.
Протокол RIP не способен обрабатывать три типа ошибок:
1. Циклические маршруты. Так как в протоколе нет механизмов выявления замкнутых маршрутов, необходимо либо слепо верить партнерам, либо принимать меры для блокировки такой возможности.
2. Для подавления нестабильностей RIP должен использовать малое значение максимально возможного числа шагов (<16).
3. Медленное распространение маршрутной информации по сети создает проблемы при динамичном изменении маршрутной ситуации (система не поспевает за изменениями). Малое предельное значение метрики улучшает сходимость, но не устраняет проблему.
Несоответствие маршрутной таблицы реальной ситуации типично не только для RIP, но характерно для всех протоколов, базирующихся на векторе расстояния, где информационные сообщения актуализации несут в себе только пары кодов: адрес места назначения и расстояние до него. Пояснение проблемы дано на рис. 59.

Рис. 59 — Возникновение циклических маршрутов
при использовании вектора расстояния
На верхней части рисунка показана ситуация, когда маршрутизаторы (GW) указывают маршрут до сети в соответствии со стрелками. На нижней части связь на участке GW1 <Сеть А> оборвана, а GW2 по-прежнему продолжает оповещать о ее доступности с числом шагов, равным 2. При этом GW1, восприняв эту информацию (если GW2 успел передать свою маршрутную информацию раньше GW1), может перенаправить пакеты, адресованные сети А, на GW2, а в своей маршрутной таблице будет характеризовать путь до сети А метрикой 3. При этом формируется замкнутая петля маршрутов. Последующая широковещательная передача маршрутных данных GW1 и GW2 не решит эту проблему быстро. Так, после очередного обмена путь от gw2 до сети А будет характеризоваться метрикой 5. Этот процесс будет продолжаться до тех пор, пока метрика не станет равной 16, а это займет слишком много циклов обмена маршрутной информацией.
Проблема может быть решена следующим образом. Маршрутизатор запоминает, через какой интерфейс получена маршрутная информация, и через этот интерфейс эту информацию уже не передает. В рассмотренном выше примере GW2 не станет посылать информацию о пути к сети А маршрутизатору GW1, от которого он получил эти данные. В этом случае в маршрутной таблице GW1 путь до А исчезнет сразу. Остальные маршрутизаторы узнают о недостижимости сети А через несколько циклов. Существуют и другие пути преодоления медленных переходных процессов. Если производится оповещение о коротком пути, все узлы-получатели воспринимают эти данные немедленно. Если же маршрутизатор закрывает какой-то путь, его отмена фиксируется остальными лишь по тайм-ауту. Универсальным методом исключения ошибок при маршрутизации является использование достаточно большой выдержки, перед тем как использовать информацию об изменении маршрутов. В этом случае к моменту изменения маршрута эта информация станет доступной всем участникам процесса маршрутизации. Но все перечисленные методы и некоторые другие известные алгоритмы, решая одну проблему, часто вносят другие. Многие из этих методов могут при определенных условиях вызвать лавину широковещательных сообщений, что также дезорганизует сеть. Именно малая скорость установления маршрутов в RIP (и других протоколах, ориентированных на вектор расстояния) и является причиной их постепенного вытеснения другими протоколами.

Рис. 60 — Формат сообщения RIP
Маршрут по умолчанию имеет адрес 0.0.0.0 (это верно и для других протоколов маршрутизации). Каждому маршруту ставится в соответствие таймер тайм-аута и «сборщика мусора». Тайм-аут-таймер сбрасывается каждый раз, когда маршрут инициализируется или корректируется. Если со времени последней коррекции прошло 3 минуты или получено сообщение о том, что вектор расстояния равен 16, маршрут считается закрытым. Но запись о нем не стирается, пока не истечет время «уборки мусора» (2мин). При появлении эквивалентного маршрута переключения на него не происходит, таким образом, блокируется возможность осцилляции между двумя или более равноценными маршрутами. Формат сообщения протокола RIP имеет вид, показанный на рис. 60. Поле версия для RIP равно 1 (для RIP-2 двум). Поле набор протоколов сети i определяет набор протоколов, которые используются в соответствующей сети (для Интернет это поле имеет значение 2). Поле расстояние до сети i содержит целое число шагов (от 1 до 15) до данной сети. В одном сообщении может присутствовать информация о 25 маршрутах. При реализации RIP можно выделить следующие режимы:

Рис. 61 — Формат сообщения RIP-2
RIP достаточно простой протокол, но, к сожалению, не лишенный недостатков:
· RIP не работает с адресами субсетей. Если нормальный 16-бит идентификатор ЭВМ класса B не равен 0, RIP не может определить, является ли ненулевая часть cубсетевым ID, или полным IP-адресом.
· RIP требует много времени для восстановления связи после сбоя в маршрутизаторе (минуты). В процессе установления режима возможны циклы.
· Число шагов важный, но не единственный параметр маршрута, да и 15 шагов не предел для современных сетей.
Протокол RIP-2 (RFC-1388, 1993 год) является новой версией RIP, которая в дополнение к широковещательному режиму поддерживает мультикастинг; позволяет работать с масками субсетей. На рис. 61 представлен формат сообщения для протокола RIP-2. Поле метка маршрута используется для поддержки внешних протоколов маршрутизации, сюда записываются коды автономных систем.
OSPF
Протокол OSPF (Open Shortest Pass First, RFC-1245-48, RFC-1583-1587, алгоритмы предложены Дикстрой) является альтернативой RIP в качестве внутреннего протокола маршрутизации. OSPF представляет собой протокол состояния маршрута (в качестве метрики используется коэффициент качества обслуживания). Каждый маршрутизатор обладает полной информацией о состоянии всех интерфейсов всех маршрутизаторов (переключателей) автономной системы. Протокол OSPF реализован в демоне маршрутизации gated, который поддерживает также RIP и внешний протокол маршрутизации BGP.
Автономная система (AS) может быть разделена на несколько областей, куда могут входить как отдельные ЭВМ, так и целые сети. В этом случае внутренние маршрутизаторы области могут и не иметь информации о топологии остальной части AS. Сеть обычно имеет выделенный (designated) маршрутизатор, который является источником маршрутной информации для остальных маршрутизаторов AS. Каждый маршрутизатор самостоятельно решает задачу оптимизации маршрутов. Если к месту назначения ведут два или более эквивалентных маршрута, информационный поток будет поделен между ними поровну. Переходные процессы в OSPF завершаются быстрее, чем в RIP. В процессе выбора оптимального маршрута анализируется ориентированный граф сети. Ниже описан алгоритм Дикстры по выбору оптимального пути. На рис. 62 приведена схема узлов (A-J) со значениями метрики для каждого из отрезков пути. Анализ графа начинается с узла A (Старт). Пути с наименьшим суммарным значением метрики считаются наилучшими. Именно они оказываются выбранными в результате рассмотрения графа («кратчайшие пути»).

Рис. 62 — Иллюстрация работы алгоритма Дикстры
Качество сервиса (QoS) может характеризоваться следующими параметрами:
· пропускной способностью канала;
· задержкой (время распространения пакета);
· числом дейтограмм, стоящих в очереди для передачи;
· загрузкой канала;
· требованиями безопасности;
· типом трафика;
· числом шагов до цели;
· возможностями промежуточных связей (например, многовариантность достижения адресата).
Определяющими являются три характеристики: задержка, пропускная способность и надежность. Для транспортных целей OSPF использует IP непосредственно, т.е. не привлекает протоколы UDP или TCP. OSPF имеет свой код (89) в протокольном поле IP-заголовка. Код TOS (type of service) в IP-пакетах, содержащих OSPF-сообщения, равен нулю, значение TOS здесь задается в самих пакетах OSPF. Маршрутизация в этом протоколе определяется IP-адресом и типом сервиса. Так как протокол не требует инкапсуляции пакетов, сильно облегчается управление сетями с большим количеством бриджей и сложной топологией (исключается циркуляция пакетов, сокращается транзитный трафик). Автономная система может быть поделена на отдельные области, каждая из которых становится объектом маршрутизации, а внутренняя структура снаружи не видна (узлы на рис. 62 могут представлять собой как отдельные ЭВМ или маршрутизаторы, так и целые сети). Этот прием позволяет значительно сократить необходимый объем маршрутной базы данных. В OSPF используется термин опорной сети (backbone) для коммуникаций между выделенными областями. Протокол работает лишь в пределах автономной системы. В пределах выделенной области может работать свой протокол маршрутизации.
На рис. 63 (см. также рис. 62) приведен пример выделения областей маршрутизации при ospf-маршрутизации в пределах автономной системы. На рис. 63 маршрутизаторы М4 и М2 выполняют функции опорной сети для других областей. В выделенных областях может быть любое число маршрутизаторов. Более толстыми линиями выделены связи с другими автономными системами.

Рис. 63 — Пример выделения областей при ospf-маршрутизации
в автономной системе (М — маршрутизаторы; c — сети)
При передаче OSPF-пакетов фрагментация нежелательна, но не запрещается. Для передачи статусной информации OSPF использует широковещательные сообщения Hello. Для повышения безопасности предусмотрена авторизация процедур.
Поле версия определяет версию протокола. Поле тип идентифицирует функцию сообщения. Поле длина пакета определяет длину блока в октетах, включая заголовок. Идентификатор области — 32-битный код, идентифицирующий область, которой данный пакет принадлежит. Все ospf-пакеты ассоциируются с той или иной областью. Большинство из них не преодолевает более одного шага. Пакеты, путешествующие по виртуальным каналам, помечаются идентификатором опорной области (backbone) 0.0.0.0. Поле контрольная сумма содержит контрольную сумму IP-пакета, включая поле типа идентификации. Контрольное суммирование производится по модулю 1. Поле тип идентификации может принимать значения 0 при отсутствии контроля доступа, и 1 при наличии контроля. Важную функцию в OSPF-сообщениях выполняет одно-октетное поле опции, оно присутствует в сообщениях типа Hello, объявление состояния канала и описание базы данных.
Любое сообщение ospf начинается с 24-октетного заголовка (рис. 64):

Рис. 64 — Формат заголовка сообщений для протокола
маршрутизации ospf
Протокол ospf использует сообщение типа Hello для взаимообмена данными между соседними маршрутизаторами.
Маршрутизаторы обмениваются сообщениями из баз данных OSPF, чтобы инициализировать, а в дальнейшем актуализовать свои базы данных, характеризующие топологию сети. Обмен происходит в режиме клиент-сервер. Клиент подтверждает получение каждого сообщения.
Сообщения об изменениях маршрутов могут быть вызваны следующими причинами:
1. Возраст маршрута достиг предельного значения (lsrefresh-time).
2. Изменилось состояние интерфейса.
3. Произошли изменения в маршрутизаторе сети.
4. Произошло изменение состояния одного из соседних маршрутизаторов.
5. Изменилось состояние одного из внутренних маршрутов (появление нового, исчезновение старого и т.д.)
6. Изменение состояния межзонного маршрута.
7. Появление нового маршрутизатора, подключенного к сети.
8. Вариация виртуального маршрута одним из маршрутизаторов.
9. Возникли изменения одного из внешних маршрутов.
10. Маршрутизатор перестал быть пограничным для данной as (например, перезагрузился).
Маршрутная таблица OSPF содержит в себе:
· IP-адрес места назначения и маску;
· тип места назначения (сеть, граничный маршрутизатор и т.д.);
· тип функции (возможен набор маршрутизаторов для каждой из функций TOS (Type of service));
· область (описывает область, связь с которой ведет к цели, возможно несколько записей данного типа, если области действия граничных маршрутизаторов перекрываются);
· тип пути (характеризует путь как внутренний, межобластной или внешний, ведущий к AS);
· цена маршрута до цели;
· очередной маршрутизатор, куда следует послать дейтограмму;
· объявляющий маршрутизатор (используется для межобластных обменов и для связей автономных систем друг с другом).
Последовательность описания метрик задается величиной кода TOS. Таблица кодов TOS, принятых в OSPF протоколе приведена ниже на рис. 65:
| OSPF-код | TOS-коды | TOS(RFC-1349) |
| Обычный сервис | ||
| Минимизация денежной стоимости | ||
| Максимальная надежность | ||
| Максимальная пропускная способность | ||
| Минимальная задержка |
Рис. 65 — Коды типа сервиса (TOS)
Преимущества OSPF:
1. Для каждого адреса может быть несколько маршрутных таблиц, по одной на каждый вид IP-операции (TOS).
2. Каждому интерфейсу присваивается безразмерная цена, учитывающая пропускную способность, время транспортировки сообщения. Для каждой IP-операции может быть присвоена своя цена (коэффициент качества).
3. При существовании эквивалентных маршрутов OSFP распределяет поток равномерно по этим маршрутам.
4. Поддерживается адресация субсетей (разные маски для разных маршрутов).
5. При связи точка-точка не требуется IP-адрес для каждого из концов. (Экономия адресов!).
6. Применение мультикастинга вместо широковещательных сообщений снижает загрузку не вовлеченных сегментов.
Недостатки:
1. Трудно получить информацию о предпочтительности каналов для узлов, поддерживающих другие протоколы, или со статической маршрутизацией.
2. OSPF является лишь внутренним протоколом.
IGRP
Протокол IGRP разработан фирмой CISCO для своих многопротокольных маршрутизаторов в середине 80-х годов. IGRP представляет собой протокол, который позволяет большому числу маршрутизаторов координировать свою работу. Основные достоинства протокола (описание протокола взято из депозитария FTP.CISCO.COM/pub/igrp.doc):
· стабильность маршрутов даже в очень больших и сложных сетях;
· быстрый отклик на изменения топологии сети;
· минимальная избыточность. IGRP не требует дополнительной пропускной способности каналов для своей работы;
· разделение потока данных между несколькими параллельными маршрутами, примерно равного достоинства;
· учет частоты ошибок и уровня загрузки каналов;
· возможность реализовать различные виды сервиса для одного и того же набора информации.
Сегодняшняя реализация протокола ориентирована на TCP/IP. Однако базовая конструкция системы позволяет использовать IGRP и с другими протоколами. IGRP имеет некоторое сходство со старыми протоколами, например, с RIP и OSPF. Здесь маршрутизатор обменивается маршрутной информацией только с непосредственными соседями. Поэтому задача маршрутизации решается всей совокупностью маршрутизаторов, а не каждым отдельно.
Для того чтобы исключить осцилляции маршрутов, протокол IGRP должен игнорировать новую информацию в течение нескольких минут после ее возникновения. OSPF-протокол вынужден использовать большую избыточность информации по сравнению с IGRP, как на уровне базы маршрутных данных, так и в процессе обмена с внешней средой.
IGRP используется в маршрутизаторах, которые имеют связи с несколькими сетями и выполняют функции переключателей пакетов. Когда какой-то объект в одной сети хочет послать пакет в другую сеть, он должен послать его соответствующему маршрутизатору. Если адресат находится в одной из сетей, непосредственно связанной с маршрутизатором, он отправляет этот пакет по месту назначения. Если же адресат находится в более отдаленной сети, маршрутизатор перешлет пакет другому маршрутизатору, расположенному ближе к адресату. Здесь также, как и в других протоколах, для хранения маршрутных данных используются специализированные базы данных.
Протокол IGRP формирует эту базу данных на основе информации, которую он получит от соседних маршрутизаторов. В простейшем случае находится один путь для каждой из сетей. Сегменты пути характеризуются используемым сетевым интерфейсом, метрикой и маршрутизатором, куда следует сначала послать пакет. Метрика — то число, которое говорит о том, насколько хорош данный маршрут. Это число позволяет сравнить его с другими маршрутами, ведущими к тому же месту назначения и обеспечивающими тот же уровень QOS. Предусматривается возможность (как и в OSPF) разделять информационный поток между несколькими доступными эквивалентными маршрутами. Пользователь может сам разделить поток данных, если два или более пути оказались почти равными по метрике, при этом большая часть трафика будет послана по пути с лучшей метрикой. Метрика, используемая в IGRP, учитывает:
· время задержки;
· пропускную способность самого слабого сегмента пути (в битах в сек);
· загруженность канала (относительную);
· надежность канала (определяется долей пакетов, достигших места назначения неповрежденными).
Время задержки предполагается равным времени, необходимом для достижения места назначения при нулевой загрузке сети. Дополнительные задержки, связанные с загрузкой, учитываются отдельно.
Среди параметров, которые контролируются, но не учитываются метрикой, находятся число шагов до цели и MTU (maximum transfer unit — размер пакета, пересылаемого без фрагментации). Расчет метрики производится для каждого сегмента пути.
Время от времени каждый маршрутизатор широковещательно рассылает свою маршрутную информацию всем соседним маршрутизаторам. Получатель сравнивает эти данные с уже имеющимися и вносит, если требуется, необходимые коррекции. На основании вновь полученной информации могут быть приняты решения об изменении маршрутов. Эта процедура типична для многих маршрутизаторов и этот алгоритм носит имя Белмана–Форда. (см. также описание протокола RIP, RFC-1058). Наилучший путь выбирается с использованием комбинированной метрики, вычисленной по формуле:
[(K1 / Be) + (K2 * Dc)] r, (1)
где K1, K2 — константы;
Be = пропускная способность канала (в отсутствие загрузки) * *(1 – загрузка канала);
Dc — топологическая задержка;
r — относительная надежность (% пакетов, успешно передаваемых по данному сегменту пути). Здесь загрузка измеряется как доля от 1.
Путь, имеющий наименьшую комбинированную метрику, считается лучшим. В такой схеме появляется возможность, используя весовые коэффициенты, адаптировать выбор маршрутов к задачам конечного пользователя.
Одним из преимуществ igrp является простота реконфигурации. В igrp маршрут по умолчанию не назначается, а выбирается из числа кандидатов.
Когда маршрутизатор включается, его маршрутные таблицы инициализируются оператором вручную или с использованием специальных файлов. На рис. 58 маршрутизатор S связан через соответствующие интерфейсы с сетями 2 и 3.

Рис. 66 — Схема сети
Таким образом, в исходный момент маршрутизатор S знает только о доступности сетей 2 и 3. За счет обмена информацией, полученной при инициализации и присланной позднее соседями, маршрутизаторы познают окружающий мир. Так, S спустя некоторое время получит информацию от маршрутизатора R о доступности сети 1 и от T — о сети 4. В свою очередь S проинформирует T о доступе к сети 1. Очень быстро информация о доступности дойдет до всех маршрутизаторов и разрозненные сети станут единым целым. Для пояснения выбора маршрута в условиях многовариантности рассмотрим схему на рис. 67

Рис. 67 — Пример сети с альтернативными маршрутами
Пусть каждый из маршрутизаторов уже вычислил комбинированную метрику для системы, изображенной на рис. 67. Для места назначения в сети 6 маршрутизатор A вычислит метрику для двух путей, через маршрутизаторы B и C. В действительности существует три маршрута из a в сеть 6:
- непосредственно в B;
- в C и затем в B;
- в C и затем в D.
Маршрутизатору A не нужно выбирать между двумя маршрутами через C. Маршрутная таблица в A содержит только одну запись, соответствующую пути к C. Если маршрутизатор A посылает пакет маршрутизатору C, то именно C решает, использовать далее путь через маршрутизаторы B или D.
Для каждого типа канала используется свое стандартное значение комбинированной задержки. Ниже приведен пример того, как может выглядеть маршрутная таблица в маршрутизаторе A для сети, изображенной таблице 6.
Таблица 6 — Пример маршрутной таблицы
| Номер сети | Интерфейс | Следующий маршрутизатор | Метрика маршрута |
| Сеть 1 | NW 1 | Нет | Непосредственная связь |
| Сеть 2 | NW 2 | Нет | Непосредственная связь |
| Сеть 3 | NW 3 | Нет | Непосредственная связь |
| Сеть 4 | NW 2 | C | |
| NW 3 | B | ||
| Сеть 5 | NW 2 | C | |
| NW 3 | B | ||
| Сеть 6 | NW 2 | C | |
| NW 3 | B |
Для того чтобы обеспечить работу с большими и сложными сетями, в IGRP введены три усовершенствования алгоритма Белмана-Форда:
1. Для описания путей вместо простой, введена векторная метрика. Расчет комбинированной метрики проводится с использованием формулы (1). Применение векторной метрики позволяет адаптировать систему с учетом различных видов сервиса.
2. Вместо выбора одного пути с минимальной метрикой, информационный поток может быть поделен между несколькими путями с метрикой, лежащей в заданном интервале. Распределение потоков определяется соотношением величин комбинированной метрики. Таким образом, используются маршруты с комбинированной метрикой меньше некоторого предельного значения M, а также с метрикой меньше V*M, где V — значение вариации M (обычно задается оператором сети).
3. Существуют определенные проблемы с вариацией. Трудно определить стратегию использования вариации V>1 и избежать зацикливания пакетов. В современных реализациях V=1.
4. Разработан ряд мер, препятствующих осцилляциям маршрутов при изменении топологии сети.
Значение вариации, отличное от единицы, позволяет использовать одновременно два или более путей с разной пропускной способностью. При дальнейшем увеличении вариации можно разрешить не только более «медленные» сегменты пути, но и ведущие в обратном направлении, что приведет с неизбежностью к «бесконечному» циклическому движению пакетов.
Протокол маршрутизации IGRP предназначен для работы с несколькими типами сервиса (TOS) и несколькими протоколами. Под типами сервиса в TCP/IP подразумевается оптимизация маршрутизации по пропускной способности, задержке, надежности и т.д. Для решения этой задачи можно использовать весовые коэффициенты K1 и K2 (формула (1) данного раздела). При этом для каждого TOS подготавливается своя маршрутная таблица. Среди мер, обеспечивающих cтабильность топологии связей, следует отметить следующее правило, которое поясняется на приведенном ниже примере (рис. 68).

Рис. 68 — Пример сети для пояснения правил формирования
маршрутной информации
Маршрутизатор A сообщает B о маршруте к сети 1. Когда же B посылает сообщения об изменении маршрутов в A, он ни при каких обстоятельствах не должен упоминать сеть 1. Т.е. сообщения об изменении маршрута, направленные какому-то маршрутизатору, не должны содержать данных об объектах, непосредственно с ним связанных. Сообщения об изменении маршрутов должны содержать:
- адреса сетей, с которыми маршрутизатор связан непосредственно;
- пропускную способность каждой из сетей;
- топологическую задержку каждой из сетей;
- надежность передачи пакетов для каждой сети;
- загруженность канала для каждой сети;
- MTU для каждой сети.
Следует еще раз обратить ваше внимание, что в IGRP не используется измерение задержек, измеряется только надежность и коэффициент загрузки канала. Надежность определяется на основе сообщений интерфейсов о числе ошибок.
Существует 4 временные константы, управляющие процессом распространения маршрутной информации (эти константы определяются оператором сети):
- период широковещательных сообщений об изменении маршрутов (это время по умолчанию равно 90 сек.);
- время существования — если за это время не поступило никаких сообщений о данном маршруте, он считается нерабочим. Это время в несколько раз больше периода сообщений об изменениях (по умолчанию в 3 раза).
- время удержания — когда какой-то адресат становится недостижим, он переходит в режим выдержки. В этом режиме никакие новые маршруты, ведущие к нему, не воспринимаются. Длительность этого режима и называется временем удержания. Обычно это время в три раза дольше периода сообщений об изменениях маршрутов;
- время удаления — если в течение данного времени не поступило сообщений о доступе к данному адресату, производится удаление записи о нем из маршрутной базы данных (по умолчанию это время в 7 раз больше периода сообщений об изменениях маршрутов).
IGRP-сообщение вкладывается в IP-пакет, это сообщение имеет следующие поля:
version — номер версии протокола 4 байта, в настоящее время равен 1. Пакеты с другим номером версии игнорируются;
opcode код операции — определяет тип сообщения и может принимать значения:
edition — код издания является серийным номером, который увеличивается при каждом изменении маршрутной таблицы. Это позволяет маршрутизатору игнорировать информацию, которая уже содержится в его базе данных;
Asystem — номер автономной системы. Согласно нормам Сisco маршрутизатор может входить в более чем одну автономную систему. В каждой AS работает свой протокол и они могут иметь совершенно независимые таблицы маршрутизации. Хотя в IGRP допускается «утечка» маршрутной информации из одной автономной системы в другую, но это определяется не протоколом, а администратором;
Ninterior, Nsystem, Nexterior — числа субсетей в локальной сети, в автономной системе и вне автономной системы, определяют числа записей в каждой из трех секций сообщения об изменениях;
checksum — контрольная сумма IGRP-заголовка и данных, для вычисления которой используется тот же алгоритм, что и в UDP, TCP и ICMP.
IGRP запрос требует от адресата прислать свою маршрутную таблицу. Сообщение содержит только заголовок. Используются поля version, opcode и asystem, остальные поля обнуляются. IP-пакет, содержащий сообщение об изменении маршрутов, имеет 1500 байт (включая IP-заголовок). Для описанной выше схемы это позволяет включить в пакет до 104 записей. Если требуется больше записей, посылается несколько пакетов. Фрагментация пакетов не применяется.
Ниже приведено описание структуры для маршрута:
| Number | 3 октета IP-адреса |
| delay | задержка в десятках микросекунд 3 октета |
| bandwidth | Пропускная способность, в Кбит/с 3 октета |
| uchar mtu | MTU, в октетах 2 октета |
| reliability | процент успешно переданных пакетов tx/rx 1 октет |
| load | процент занятости канала 1 октет |
| hopcount | Число шагов 1 октет |
Субполе описание маршрута Number определяет IP-адрес места назначения, для экономии места здесь используется только 3 его байта. Если поле задержки содержит только единицы, место назначения недостижимо.
Пропускная способность измеряется в величинах, обратных бит/сек, умноженных на 1010. (Т.е., если пропускная способность равна N Кбит/с, то ее измерением в IGRP будет 10000000/N.). Надежность измеряется в долях от 255 (т.е. 255 соответствует 100 %). Загрузка измеряется также в долях от 255, а задержка в десятках миллисекунд.
Ниже приведены значения по умолчанию для величин задержки и пропускной способности.
Комбинированная метрика в действительности вычисляется по следующей формуле (для версии Cisco 8.0(3)):
Метрика = [K1*пропускная_способность +
+(K2*пропускная способность)/(256 – загрузка) + K3*задержка] * * [K5/(надежность + K4)].
Если K5 == 0, член надежности отбрасывается. По умолчанию в IGRP K1 == K3 == 1, K2 == K4 == K5 == 0, а загрузка лежит в интервале от 1 до 255.
Таблица 7 — Значения величин задержки и пропускной способности, используемые по умолчанию
| Вид среды | Задержка | Пропускная способность |
| Спутник | 200,000 (2 сек.) | 20 (500 Мбит/c) |
| Ethernet | 100 (1 мсек.) | 1,000 |
| 1,544 Мбит/c | 2000 (20 мсек.) | 6,476 |
| 64 Кбит/c | 156,250 | |
| 56 Кбит/c | 178,571 | |
| 10 Кбит/c | 1,000,000 | |
| 1 Кбит/c | 10,000,000 |
EIGRP
В начале 90-х годов разработана новая версия протокола IGRP — EIGRP с улучшенным алгоритмом оптимизации маршрутов, сокращенным временем установления и масками субсетей переменной длины. EIGRP поддерживает многие протоколы сетевого уровня. Рассылка маршрутной информации здесь производится лишь при измении маршрутной ситуации. Протокол периодически рассылает соседним маршрутизаторам короткие сообщения Hello. Получение отклика означает, что сосед функционален и можно осуществлять обмен маршрутной информацией. Протокол EIGRP использует таблицы соседей (адрес и интерфейс), топологические таблицы (адрес места назначения и список соседей, объявляющих о доступности этого адреса), состояния и метки маршрутов. Для каждого протокольного модуля создается своя таблица соседей. Протоколом используются сообщения типа hello (мультикастная адресация), подтверждение (acknowledgent), актуализация (update), запрос (query, всегда мультикастный) и отклик (reply, посылается отправителю запроса). Маршруты здесь делятся на внутренние и внешние — полученные от других протоколов или записанные в статических таблицах. Маршруты помечаются идентификаторами их начала. Внешние маршруты помечаются следующей информацией:
· Идентификатор маршрутизатора EIGRP, который осуществляет рассылку информации о маршруте.
· Номер AS, где расположен адресат маршрута.
· Метка администратора.
· Идентификатор протокола.
· Метрика внешнего маршрута.
· Битовые флаги маршрута по умолчанию.
Протокол EIGRP полностью совместим с IGRP, он обеспечивает работу в сетях IP, Apple Talk и Novell.
BGP
Протокол BGP (RFC-1267, BGP-3; RFC-1268; RFC-1467, BGP-4; -1265-66, 1655) разработан компаниями IBM и CISCO. Главная цель BGP — сократить транзитный трафик. Местный трафик либо начинается, либо завершается в автономной системе (AS); в противном случае — это транзитный трафик. Системы без транзитного трафика не нуждаются в BGP (им достаточно EGP для общения с транзитными узлами). Но не всякая ЭВМ, использующая протокол BGP, является маршрутизатором, даже если она обменивается маршрутной информацией с пограничным маршрутизатором соседней автономной системы. AS передает информацию только о маршрутах, которыми она сама пользуется. BGP — маршрутизаторы обмениваются сообщениями об изменении маршрутов (UPDATE-сообщения, рис. 69). Максимальная длина таких сообщений составляет 4096 октетов, а минимальная 19 октетов. Каждое сообщение имеет заголовок фиксированного размера. Объем информационных полей зависит от типа сообщения.
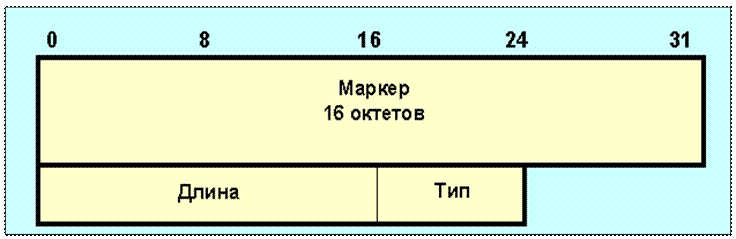
Рис. 69 — Формат BGP-сообщений об изменениях маршрутов
Поле маркер содержит 16 октетов. Маркер может использоваться для обнаружения потери синхронизации в работе BGP-партнеров. Поле длина имеет два октета и определяет общую длину сообщения в октетах, включая заголовок. Значение этого поля должно лежать в пределах 19-4096. Поле тип представляет собой код разновидности сообщения и может принимать следующие значения:
| OPEN | (открыть) | |
| UPDATE | (изменить) | |
| NOTIFICATION | (внимание) | |
| KEEPALIVE | (еще жив) |
После того как связь на транспортном протокольном уровне установлена, первое сообщение, которое должно быть послано, — это OPEN. При его успешном прохождении партнер должен откликнуться сообщением KEEPALIVE («Еще жив»). После этого возможны любые сообщения. Кроме заголовка сообщение open содержит поля (рис. 70):

Рис. 70 — Формат сообщения open
Поле версия описывает код версии используемого протокола, на сегодня для BGP он равен 4. Двух-октетное поле моя автономная система определяет код AS отправителя. Поле время сохранения характеризует время в секундах, которое отправитель предлагает занести в таймер сохранения. После получения сообщения OPEN BGP — маршрутизатор должен выбрать значение времени сохранения. Обычно выбирается меньшее из полученного в сообщении open и значения, определенного при конфигурации системы (0–3сек). Время сохранения определяет максимальное время в секундах между сообщениями KEEPALIVE и UPDATE или между двумя UPDATE-сообщениями. Каждому узлу в рамках BGP приписывается 4-октетный идентификатор (BGP-identifier, задается при инсталляции и идентичен для всех интерфейсов локальной сети). Если два узла установили два канала связи друг с другом, то согласно правилам, должен быть сохранен канал, начинающийся в узле, BGP-идентификатор которого больше. Предусмотрен механизм разрешения проблемы при равных идентификаторах.
Вся маршрутная информация хранится в специальной базе данных RIB (routing information base). Маршрутная база данных BGP состоит из трех частей:
| 1. | ADJ-RIBS-IN: | Запоминает маршрутную информацию, которая получена из update-сообщений. Это список маршрутов, из которого можно выбирать. (policy information base — PIB). |
| 2. | LOC-RIB: | Содержит локальную маршрутную информацию, которую BGP — маршрутизатор отобрал, руковод-ствуясь маршрутной политикой, из ADJ-RIBS-IN. |
| 3. | ADJ-RIBS-OUT: | Содержит информацию, которую локальный BGP- маршрутизатор отобрал для рассылки соседям с помощью UPDATE-сообщений. |
Так как разные BGP-партнеры могут иметь разную политику маршрутизации, возможны осцилляции маршрутов. Для исключения этого необходимо выполнять следующее правило: если используемый маршрут объявлен не рабочим (в процессе корректировки получено сообщение с соответствующим атрибутом), до переключения на новый маршрут необходимо ретранслировать сообщение о недоступности старого всем соседним узлам.
Протокол BGP позволяет реализовать маршрутную политику.
Политика отражается в конфигурационных файлах BGP. Маршрутная политика — это не часть протокола, она определяет решения, когда место назначения достижимо несколькими путями, политика отражает соображения безопасности, экономические интересы и пр. Количество сетей в пределах одной AS не лимитировано. BGP использует три таймера:
Connectretry (сброс при инициализации и коррекции; 120 сек).
Holdtime (пуск при получении команд Update или Keepalive; 90 сек).
Кeepalive (пуск при посылке сообщения Keepalive; 30 сек).
BGP отличается от RIP и OSPF тем, что использует TCP в качестве транспортного протокола. Две системы, использующие BGP, связываются друг с другом и пересылают посредством TCP полные таблицы маршрутизации. В дальнейшем обмен идет только в случае каких-то изменений. ЭВМ, использующая BGP, не обязательно является маршрутизатором. Сообщения обрабатываются только после того, как они полностью получены.
BGP является протоколом, ориентирующимся на вектор расстояния. Вектор описывается списком AS по 16 бит на AS. BGP регулярно (каждые 30сек) посылает соседям TCP-сообще-ния, подтверждающие, что узел жив (это не то же самое что «Keepalive» — функция в TCP). Если два BGP-маршрутизатора попытаются установить связь друг с другом одновременно, такие две связи могут быть установлены. Такая ситуация называется столкновением, одна из связей должна быть ликвидирована. При установлении связи маршрутизаторов сначала делается попытка реализовать высший из протоколов (например, BGP-4), если один из них не поддерживает эту версию, номер версии понижается.
Протокол BGP-4 является усовершенствованной версией (по сравнению с BGP-3). Эта версия позволяет пересылать информацию о маршруте в рамках одного IP-пакета. Концепция классов сетей и субсети находятся вне рамок этой версии. Для того чтобы приспособиться к этому, изменена семантика и кодирование атрибута AS_PASS. Введен новый атрибут LOCAL_PREF (степень предпочтительности маршрута для собственной AS), который упрощает процедуру выбора маршрута. Атрибут INTER_AS_METRICS переименован в MULTI_EXIT_DISC (4 октета; служит для выбора пути к одному из соседей). Введены новые атрибуты ATOMIC_AGGREGATE и AGGREGATOR, которые позволяют группировать маршруты. Структура данных отражается и на схеме принятия решения, которая имеет три фазы:
1. Вычисление степени предпочтения для каждого маршрута, полученного от соседней AS, и передача информации другим узлам местной AS.
2. Выбор лучшего маршрута из наличного числа для каждой точки назначения и укладка результата в LOC-RIB.
3. Рассылка информации всем соседним AS согласно политике, заложенной в RIB. Группировка маршрутов и редактирование маршрутной информации.
|
Просмотров 2416 |
|
|
