Главная Обратная связь
Дисциплины:
Архитектура (936)
Биология (6393)
География (744)
История (25)
Компьютеры (1497)
Кулинария (2184)
Культура (3938)
Литература (5778)
Математика (5918)
Медицина (9278)
Механика (2776)
Образование (13883)
Политика (26404)
Правоведение (321)
Психология (56518)
Религия (1833)
Социология (23400)
Спорт (2350)
Строительство (17942)
Технология (5741)
Транспорт (14634)
Физика (1043)
Философия (440)
Финансы (17336)
Химия (4931)
Экология (6055)
Экономика (9200)
Электроника (7621)

Правила створення XML-документа
|
|
ТЕХНОЛОГІЇ XML
Мова XML – Extensible Markup Language (Розширювана Мова Розмітки),з'явилася відносно недавно, але фактично перетворилась в невід’ємну технологію уніфікованих форматів обміну даними та структурованого подання електронних документах в різних інформаційних системах. Мова XML стала основою WEB технологій, технологій електронного бізнесу, універсальним механізмом взаємодії програмних систем і способом представлення інформації в СКБД.
Зовні мова XML схожа на мову HTML (тегові операторні дужки), але функціонально має більш широку сферу застосування. На базі XML завдяки її універсальності з'явилося багато новітніх технологій обміну даними між додатками, зберігання даних в БД і універсалізації доступу до даних в WEB-додатках.
Основи та компоненти XML
XML був створений в World Wide Web Consortium (W3C) для подолання обмежень мови HTML, Hypertext Markup Language (Гіпертекстова Мова Розмітки), яка є основою всіх Web-сторінок.
Як і HTML, XML базується на SGML - Standard Generalized Markup Language (Стандартна Узагальнена Мова Розмітки). Хоча SGML десятиліттями використовувався у видавничій справі, він є складним, що відлякує багато людей, які могли б його використовувати (SGML також розшифровується як "Sounds great, maybe later" - "Звучить прекрасно, можливо пізніше"). XML був розроблений з прицілом на Web.
Мова HTML - дозволяє проглянути прості теги HTML практично на будь-якому пристрої від PDA до мейнфрейма і підтримує перетворення розмітки HTML в голос і в інші формати за допомогою відповідних інструментів. Але HTML володіє суттєвою вадою, яка полягає в тому, що HTML був розроблений з метою лише розмітки електронних документів для їх візуалізації та візуального подання користувачам. Для розуміння сутності вади розглянемо документ:
| <p><b>Mrs. Mary McGoon</b><br>1401 Main Street<br>Anytown, NC 34829</p> | Щоб відобразити HTML, браузер просто слідує інструкціям в HTML-документі. Тег параграфа (<p>) повідомляє браузеру, що потрібно відобразити новий рядок, звичайно, з пропуском рядка перед ним, а два тега розриви (<br>) повідомляють браузеру, що потрібно перейти на новий рядок без пропусків між рядками. Браузер чудово форматує документ, але програма все ж таки не знає, що це адреса |
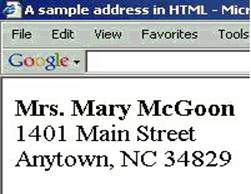
|
Люди мають інтелект, що дозволяє нам зрозуміти значення та призначення більшості електронних документів. Навіть не проглядаючи приведений вище HTML-документ в браузері, можемо зрозуміти, що це чиясь поштова адреса.
Комп’ютер зробити цього не може. Теги в цьому документі вказують браузеру, як відображати інформацію, але теги не вказують браузеру, що це за інформація, тобто не структурують зміст або семантику документа.
Для подолання цієї вади у XML, тегам в документі призначується певне значення, що дозволяє комп’ютеру здійснювати операції над інформацією.
<address> <name> <title>Mrs.</title> <first-name> Mary</first-name> <last-name> McGoon</last-name> </name> <street>1401 Main Street</street> <city>Anytown</city> <state>NC</state> <postal-code>34829</postal-code></address>Наприклад, для виділення поштового коду з цього документа достатньо знайти вміст, яке обрамлено тегами <postal-code> і </postal-code>, або контейнер, званий елементом <postal-code>.
Мова XML, в найзагальнішому вигляді, – це набір простих правил для опису вкладених текстових структур даних. Дані, які описані на мові XML, називаються XML-документами. Документ XML це сукупність елементів. Сам документ також є елементом.
Документ XML містить декілька компонентів, проте найбільш головними є три компонента, що використовуються для породження складових структурованого XML-документа:
· теги;
· елементи;
· атрибути.
Тег – це текст (заголовок) між лівою кутовою дужкою (<) та правою кутовою дужкою (>).У прикладі Початкові теги (такі, як <name>) та Кінцеві теги (такі, як </name>). .
Елемент – це структурна одиниця XML-документа, що визначається початковим тегом, кінцевим тегом і всім, що є між ними. Опис елементів обов'язково включає ключові тегі (заголовки) початковий і кінцевий, які повинні співпадати по найменуванню <address> – </address>.Наявність слова між тегами визначає непорожній елемент. Елемент може мати довільне число атрибутів (властивостей). Елементи можуть містити інші елементи, які можуть розташовуватися в довільному порядку, але написані за визначеними правилами. У прикладі елемент <name> містить два дочірні елементи: <title>, <first-name> і <last-name>.
В XML документі обов'язково повинен бути головний елемент (root - address). Допускається елемент без вмісту: </address >.
Атрибут - це пара ім'я="значення" усередині початкового тега елементу. Атрибути задають унікальні властивості елементів і можуть бути отриманий при обробці документа. Наприклад <city state="NC">Anytown</city>. У прикладі state є атрибутом елементу <city>; у попередньому прикладі <state> був елементом. Атрибути мають значення і тип.
Крім атрибутів в елементи може бути включений звичайний текст, наприклад: 1401 Main Street
Більшість XML-документів починаються з XML-заголовку, який забезпечує базову інформацію про документ для парсера. Вживання XML-заголовку рекомендується, але не є обов'язковим. Якщо воно є, воно повинне бути першим, що є в документі. В заголовку документа поміщається оголошення XML, в якому вказується мова розмітки документа, номер його версії і додаткова інформація
Коментарі. Коментарі можуть з'являтися де завгодно в документі; вони можуть навіть з'являтися перед кореневим елементом. Коментар починається з <!-- і закінчується -->. Коментар не може не містити подвійного дефіса (--) ніде, окрім як в кінці; за цим виключенням, коментар може містити що завгодно. Коментарі пропускаються парсером (аналізатором) і тому при розборі структури документа як значуща інформація не розглядаються.
Найважливіше, що будь-яка розмітка усередині коментаря ігнорується; якщо ви хочете видалити великий розділ з XML-документа, просто укладете цей розділ в коментар. (Щоб відновити закоментований розділ, просто видалите теги коментаря.)
<!-- Це PI для Cocoon: -->
<?cocoon-process type="sql"?>
Інструкції обробки. Інструкції, призначені для аналізаторів мови, є розміткою призначеної для певного коду, описуються в XML документі за допомогою спеціальних тегів - <? і ?>. Програма клієнта використовує ці інструкції для управління процесом розбору документа. Найбільш часто інструкції використовуються при визначенні типа документа (наприклад <? Xml version=”1.0”?>) або створенні простору імен[11].
У прикладі вище це інструкція обробки (іноді звана PI) для Cocoon, бібліотеки обробки XML від Apache Software Foundation. Коли Cocoon обробляє XML-документ, він шукає інструкції обробки які починаються з cocoon-process, а потім обробляє XML-документ відповідно до них. У даному прикладі атрибут type="sql" повідомляє Cocoon, що the XML-документ містить оператора SQL.
Спеціальні символи. Для того, щоб включити в документ символ, що використовується для визначення яких-небудь конструкцій мови (наприклад, символ кутової дужки) і не викликати при цьому помилок в процесі розбору такого документа, потрібно використовувати його спеціальний символьний або числовий ідентифікатор. Наприклад &lt; &gt; &quot; або $(десяткова форма запису)  (шестнадцатеричная) і т.д.
Простори імен.
Потужність XML походить від його гнучкості, з того факту, що будь хто з мільйонів інших людей може визначати власні теги, щоб описувати дані. У прикладі XML-документа для імені і адреси людини елемент <title> для ввічливого іменування людини, цілком відповідний вибір для елементу імені. Якщо ж ви працюєте з книгосховищем, онлайна, ви можете створити елемент <title> для назви книги. Якщо ж ви працюєте із заставною компанією, онлайна, ви можете створити елемент <title> для частини заставного документа. Все це розумні варіанти, але всі вони створюють елементи з одним і тим же ім'ям. Як ви повідомите, що даний елемент <title> відноситься до людини, книги або частини застави? За допомогою просторів імен.
Щоб використовувати простір імен, ви визначаєте префікс простору імен і відображаєте його на певний рядок. От так ви можете розрізнити префікси простору імен для наших трьох елементів <title>:
<?xml version="1.0"?>
<customer_summary
xmlns:addr="http://www.xyz.com/addresses/"
xmlns:books="http://www.zyx.com/books/"
xmlns:mortgage="http://www.yyz.com/title/"
>
... <addr:name><title>Mrs.</title> ... </addr:name> ...
... <books:title>Lord of the Rings</books:title> ...
... <mortgage:title>NC2948-388-1983</mortgage:title> ...
В даному прикладі три префікси простору імен: addr, books, і mortgage. Відмітьте, що визначення простору імен для певного елементу означає, що всі його дочірні елементи належать до того ж простору імен. Перший елемент <title> належить до простору імен, оскільки до нього належить його батьківський елемент <addr:Name> .
Одне останнє зауваження: Рядок у визначенні простору імен є тільки рядком. Так, ці рядки виглядають як URL, але ними не є. Ви можете визначити xmlns:addr="mike", і це також працюватиме. Тільки одне важливо відносно рядка простору імен: воно має бути унікальним; от чому більшість просторів імен виглядають як URL. XML-парсер не звертається до http://www.zyx.com/books/, щоб знайти DTD або схему, він просто використовує цей текст як рядок. Це дещо збиває з пантелику, але саме так працюють простори імен.
На рисунку, розташованому нижче, представлений вид найпростішого XML документа. Він складається із заголовка і тексту документа, якій включає інші елементи і їх атрибути (в прикладі елементи: article, part, picture; атрибути: version, file). Крім того, в документі може розташовуватися звичайний текст.

Рис. 1. Приклад простого XML документа.
Фактично, XML є новою технологію інтеграції програмних компонент. Основними перевагами використання XML відповідно до задач кадастрових систем є:
1. Інтеграція даних з різних джерел. XML можна використовувати для об'єднання різнорідних структурованих даних на середньому рівні трьохрівневих Web-систем, баз даних.
2. Локальна обробка даних. Отримані дані у форматі XML можна розбирати, обробляти і відображати безпосередньо на клієнті без додаткових звернень до серверу.
3. Перегляд і маніпулювання даними в різних розрізах. Отримані дані можуть оброблятися і бути видимим клієнтом різними способами залежно від потреб кінцевого користувача.
4. Можливість часткового оновлення даних. За допомогою XML можна обновляти тільки ту частину структурованих даних, яка була змінена, а не всю структуру цілком.
Всі ці переваги роблять XML незамінним інструментом для розробки гнучких засобів пошуку інформації в базах даних, могутніх трьохрівневих Web-додатків, а також додатків, що підтримують транзакції. Іншими словами, за допомогою XML можна формувати запити до баз даних різних структур, що дозволяє здійснювати пошук інформації в чисельних несумісних один з одним базах даних. Використовування XML на середньому рівні трьохрівневих Web-додатків дозволяє здійснювати ефективний обмін даними між клієнтами і серверами систем електронної комерції.
Правила створення XML-документа
Особливістю XML-документів є наявність встановлених строгих правил, яким повинен XML-документ: Специфікація XML вимагає, щоб парсер відбраковував будь-який XML-документ, в якому не витримано основних правил. Створені ці правила навмисно, щоб обійти неоднозначність, що виникає в погано структурованих HTML-документах, недбала розмітка яких приймається більшістю парсерів.
Парсер - це частина програмного коду, яка намагається прочитати документ і інтерпретувати його вміст.
В загальному випадку XML-документи повинні задовольняти наступним вимогам:
1. Кожний відкриваючий тег, що визначає деяку частину даних в документі, обов'язково повинен супроводитися закриваючим (тобто, на відміну від HTML, не можна опускати закриваючі тэги).
2. Вкладеність тэгов в XML строго контролюється, тому необхідно стежити за порядком проходження відкриваючих і закриваючих тэгов.
3. В XML враховується регістр символів.
4. Вся інформація, розташована між початковим і кінцевим тегами, розглядається в XML як дані, і тому враховуються всі символи форматування (тобто пропуски, переклади рядків, табуляції не ігноруються, як в HTML).
5. Кожний XML-документ повинен мати унікальний кореневий елемент. В нашому прикладі таким елементом є елемент <address>.
6. Всі значення атрибутів, що використовуються у визначенні тэгов, повинні бути укладений в лапки.
Якщо XML-документ не порушує приведені вище правила, то він називається формально-правильним.
Аналіз XML-документів
Отримання даних з XML-документа, а також перевірка коректності XML-документів забезпечується аналізаторами (parsers) XML-документів. Якщо XML-документ є формально-правильним, то всі аналізатори, що призначені для опрацювання XML-документів, зможуть працювати з ним коректно.

XML-аналізатори дозволяють у випадку якщо задані в документі конструкції мови є синтаксично коректними, правильно витягувати визначувані ними елементи документа і передавати їх прикладній програмі, що виконує необхідні дії по відображенню. Тобто після розбору XML-документа в більшості випадків, прикладній програмі надається об'єктна модель, що відображає вміст отриманого XML-документа, і засоби, необхідні для роботи з нею (проходу по дереву елементів).
Прикладом XML-аналізатора може служити вбудований в Microsoft Internet Explorer версії 5.0 XML-аналізатор MSXML. Він дозволяє читати дані з XML-файлу, обробляти їх, генерувати дерево елементів, відображати дані з використанням стильових таблиць XSL, а також, використовуючи DOM, представляти всі елементи даних у вигляді об'єктів.
На сьогоднішній день існує два способи контролю правильності XML-документа і визначення елементів, які використовуються для представлення даних:
· DTD-визначення (Document Type Definition – Визначення Типу Документа). DTD визначає елементи, які можуть з'являтися в XML-документі, порядок, в якому вони можуть з'являтися, як вони можуть бути вкладені один в одного і інші основні деталі структури XML-документа. DTD є частиною початкової специфікації XML і вони дуже схожі на DTD в SGML;.
· схеми даних (Semantic Schema, XML Schema, схема XML). Схема може визначити все те в структурі документа, що вміщується в DTD, і може також визначити типи даних і складніші правила, чим DTD. W3C розробила специфікацію XML Schema через пару років після початкової специфікації XML.
Якщо XML-документ створюється і пересилається з використанням DTD-описів або схем (Schemas), то він називається валідним (правильним). XML-документ, якій відповідає правилам опису даних, але не мають DTD або схеми називається правильно-форматованим. Неправильними є XML-документи, в яких не дотримуються синтаксичних правил, визначених у специфікації XML.

Рис. . Перевірка документа XML на основі DTD або Schemas
DTD. Синтаксис DTD своєрідний і потребує додаткових зусилль при створенні таких документів (складність DTD є однією з причин того, що використовування SGML, вимагаючого визначення DTD для будь-якого документа, не отримало такого широкого розповсюдження як, наприклад, HTML).
В правилах DTD описуються елементи і їх допустимий вміст, атрибути і їх допустимі значення. Наприклад, при описі за допомогою DTD повинен бути заданий тип документа, задані елементи і їх допустимі атрибути:
В XML використовувати DTD не обов'язково - документи, створені без цих правил, правильно оброблятимуться програмою-аналізатором, якщо вони задовольняють основним вимогам синтаксису XML. Проте контроль за типами елементів і коректністю відносин між ними в цьому випадку повністю покладатиметься на автора документа.
В DTD для XML використовуються наступні типи правил:
· правила для елементів і їх атрибутів;
· опису категорій (макроозначень);
· опис форматів бінарних даних.
Всі вони описують основні конструкції мови - елементи, атрибути, символьні константи зовнішні файли бінарних даних.
DTD дозволяє вам задати основну структуру XML-документа.
<!-- address.dtd -->
<!ELEMENT address (name, street, city, state, postal-code)>
<!ELEMENT name (title? first-name, last-name)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT first-name (#PCDATA)>
<!ELEMENT last-name (#PCDATA)>
<!ELEMENT street (#PCDATA)>
<!ELEMENT city (#PCDATA)>
<!ELEMENT state (#PCDATA)>
<!ELEMENT postal-code (#PCDATA)>
Цей DTD визначає всі елементи, використовувані в прикладі документа. Воно визначає три основні речі:
Елемент <address> містить <name>, <street>, <city>, <state> і <postal-code>. Всі ці елементи повинні бути присутніми і саме в такому порядку.
Елемент <name> містить необов'язковий елемент <title> (знак питання означає, що <title> є необов'язковим), за яким слідує елемент <first-name> і елемент <last-name>.
Всі інші елементи містять текст. (#PCDATA позначає розбирані символьні дані; ви не можете включати інші елементи в ці елементи.)
Хоча DTD простий, він прояснює, які комбінації елементів є допустимими. Документ адреси, яка має елемент <postal-code> перед елементом <state>, не є правильним, як і документ, який не має елементу <last-name>.
Символи в DTD. Є декілька символів, використовуваних в DTD для індикації того, як часто (або коли) що-небудь може з'являтися в XML-документі:
· Кома показує список обов’язкових елементів.
· Знак питання показує, що елемент є необов'язковим; він може з'являтися один раз або не з'являтися взагалі.
· Знак плюс показує, що елемент з'являється хоч би один раз, але може з'являтися і скільки завгодно раз.
· Зірочка показує, що елемент може з'являтися скільки завгодно раз, включаючи нуль.
· Вертикальна межа показує список варіантів; ви можете вибрати тільки один елемент із списку.
Визначення атрибутів. За допомогою DTD ви можете визначити атрибути для елементів, що з'являються у вашому XML-документі, а також:
· Визначити, які атрибути є обов'язковими
· Визначити значення за умовчанням для даного атрибуту
· Перерахувати допустимі значення для даного атрибуту
Схема даних це спосіб створення правил побудови XML-документів, тобто завдання допустимих імен, типів, атрибутів і відносин елементів в XML-документі. Схеми є альтернативним способом створення правил побудови XML-документів. В порівнянні з DTD-описами, схеми володіють більш могутніми засобами для визначення складних структур даних, забезпечують більш зрозумілий спосіб опису граматики мови, здатні легко модернізуватися і розширятися. Безумовною гідністю схем є також те, що вони дозволяють описувати правила для XML-документа засобами самого ж XML. З цієї точки зору мову XML можна назвати тим, що самоописується.
Схеми XML мають декілька переваг в порівнянні з DTD:
· Схеми XML використовують синтаксис XML. Іншими словами, схема XML є XML-документом. Це означає, що ви можете обробляти схему так само, як і будь-який інший документ. Наприклад, ви можете написати таблицю стилів XSLT, яка перетворить схему XML Web-форму разом з автоматичною генерацією коду JavaScript, який перевірятиме дані у міру їх введення.
· Схеми XML підтримують типи даних. Хоча DTD виконує підтримку типів даних, воно розглядає ці типи даних тільки з погляду публікації. Схеми XML підтримують всі початкові типи даних DTD (такі, як ID і посилання ID). Вони також підтримують цілі і дійсні числа, дати і часи, рядки, URL і інші типи даних, корисні для обробки і перевірки даних.
· Схеми XML є розширюваними. Окрім типів даних, визначених в специфікації XML schema, ви можете також створювати власні типи і можете створювати типи-спадкоємці на базі інших типів даних.
· Схеми XML мають могутніші вирази. Наприклад, за допомогою схем XML ви можете визначити, що будь-яке значення атрибуту <state> не може бути довше двох символів або що будь-яке значення елементу <postal-code> повинно відповідати регулярному виразу [0-9]{5}(-[0-9]{4})?.
Проте це не означає, що схеми можуть повністю замінити DTD- описи - цей спосіб визначення граматики мови використовується зараз практичними всіма верифікуючими аналізаторами XML і, більш того, самі схеми, як звичайні XML-елементи, теж описуються DTD. Але серйозні можливості нової мови і його відносна простота, безумовно, дають підстави стверджувати, що майбутній стандарт знайде широке застосування як зручного і ефективного засобу перевірки коректності складання документів.
При описі за допомогою схем файл опису граматики XML в самому найпростішому випадку може бути виглядати так:
<?xml version="1.0" encoding="Windows-1251"?>
<Schema xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:datatypes">
<AttributeType name="id" required="no dt":type="string"/>
<ElementType name="title dt":type="string">
</ElementType>
<ElementType name="part">
<attribute type="id"/> <element type="title"/>
</ElementType>
<Element Type name="picture dt":type="string"></ElementType>
<ElementType name="article">
<element type="part"/>
<element type="picture"/>
</ElementType>
<ElementType name="Book">
<element type="article"/></ElementType>
</Schema>
В даній схемі документа визначається головний документ Book, який містить елементи article. Елемент article містить елементи part і picture. Для елемента part описаний атрибут id, якою повинен бути типу string і є необов'язковим. Якщо при перевірці на основі схем або DTD виявлена помилка, то в програму або броузер повідомляється і її типі, місці і коді. Використовування схем правил, дозволяє задати практично будь-яку граматику, яка піддається формалізованій обробці. Відзначу, що і схеми даних можна побудувати в програмі, тобто ми дістаємо можливість генерації схеми мови і виконання автоматизовану синтаксичну і семантичну перевірку документів XML на їх основі.
Технологічні процеси XML
До основних технологічних процесів над XML-документами (рис. ) відносяться:
· обробка даних;
· обмін даними;
· зберігання даними;
· перевірка даних;
· перетворення даних;
· генерація даних.

Рис. Узагальнений погляд на XML технології.
В обробці XML інформації беруть участь різні програмні додатки СУБД XML, XSL процесори і WEB сервер-клієнт компоненти.
Дані на малюнку представлені у форматі XML. Вони необхідні: для безпосереднього зберігання (XML документ), для опису структур даних (XML схеми) і для перетворення даних (XSL правила-програми).
Мова XML забезпечує опис складних структур даних. В першу чергу це: списки, масиви, дерева. Описи можуть мати, залежно від типів елементів, вкладену структуру. На рис., представленому нижче, даний опис деревовидної структури даних.

Рис. . Представлення структур даних у вигляді дерева.
Якщо використовувати спеціальні атрибути або спеціальні елементи, то можна описати і мережні структури даних. В першому випадку атрибути описують посилання на інші вузли мережної структури. Якщо взяти до уваги, що атрибутів може бути довільне число (відзначу, що вони можуть формуватися і оброблятися в додатках), то можна описати розмічений граф довільного вигляду. Якщо для визначення зв'язків виділити окремі елементи типу зв'язок (як в реляційних БД), то аналогічно можна описати довільну мережну структуру даних. Наприклад, дані наступні описи за допомогою елементів-зв'язків і атрибутів:
<Узел id="K Link="1"></Узел>"
<Связь from="1"to="2"/>,
на рис. нижче проілюстрована така сіть.
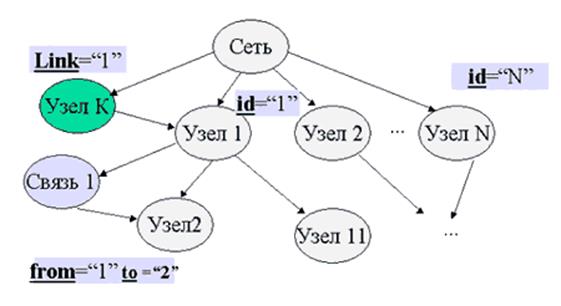
Рис. . Представлення мережних структур в XML.
|
Просмотров 2151 |
|
|
